Unlocking the Beauty of Patterns in Binary Data
Software engineers usually don’t deal with binary data directly. Most data is stored in well-known, open-format files and manipulated through libraries that know how to handle them. So bits and bytes are almost never in a developer’s mind. Apparently, they even scare people: all that random, unreadable mess not meant for human consumption…
When working with legacy code you might come up with an obscure binary file with unknown format and need to crack it. Diving into the binary world might present unknown beauty, and making sense of all those bits can be very rewarding. It probably comes from my electronics background, but I do love bits and bytes. I find infinite pleasure in diving into a pool of apparently random data and finding patterns that let me decode it, and make sense of it.
At Corgibytes, I was assigned a project where an application showed data that we knew was stored in a bunch of binary files. We needed to be able to extract that information ourselves directly from the files, but didn’t have their format. I was so excited! I’m always amazed at how people find it surprising that I love that challenge! How can someone not love it? It’s playing detective-archeologist and uncovering the beauty scheme of binary data.
This is how I go about it.
General Process
The binary file data
This is an example of some data an application might show us:
| Birthdate | Name | Hobbies | Number of pets |
|---|---|---|---|
| 12/07/1975 | Catalina De la cuesta | Sewing Reading Singing Dancing | 1 |
| 03/24/1985 | Gabriel Doe Smith | Sewing Reading Dancing | 2 |
| 02/20/2017 | Cathrin Rani Balwinder | Painting Sewing Movies Running | 10 |
| 06/22/1998 | Mikael Gopinatha Levi | Singing Movies | 0 |
This is the data in the binary file:
000034440F00CD0000000000008800000000000000688E922B000000436174616C696E61204465206C6120637565737461000000000100D8007C44DE6F0000004761627269656C20446F6520536D69746800000000000000000200C0005CD1585A0100004361746872696E2052616E692042616C77696E6465720000000A000F0038A640D10000004D696B61656C20476F70696E61746861204C65766900000000000011See? It doesn’t bite or bark. It’s lovely! Maybe you don’t quite see it yet, but trust me.
All the data the application is showing us is there. We just have to uncover it.
Using the right tool
The first thing I’ll do is open it with a tool that will help me visualize the data both in hexadecimal representation and ascii (human readable) representation. I use Synalyze It! because it has some nice features to build “the grammar,” as they call it.
Creating the grammar
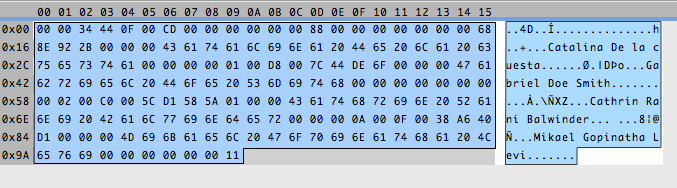
Yes!! We start to see it. The easiest parts to discover are always the parts of the file that contain text. That will help us figure out other things. I will assume, because it looks like it, that the records are stored in fixed-size chunks of data. And measuring the distance between two names can help me confirm that:
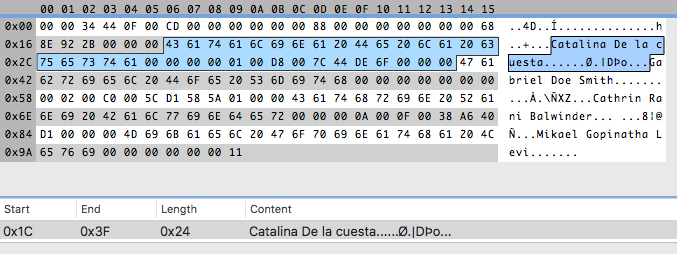
Here, you see the distance between the first and the second is 0x24, that is 36 bytes. And that is the same distance between the others. So my assumption was right, and the record size is 36. You could think the size of the file should be a multiple of this number, but it’s usually not the case. In this case, the file size is 164. 164 / 36 = 4.555… So, we have four and a half records? That doesn’t make any sense. That’s because what actually happens is that files can have some bytes at the beginning with general information about the table. I call them header bytes. The size of four records is 144, that leaves us 20 bytes. Ah, a round number! I like those. They make me feel confident that this is indeed a header.
I will use the magic of Synalyze It! and start creating my grammar:
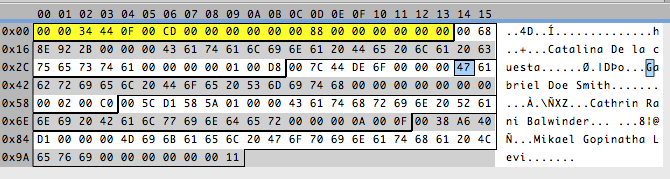
It’s beginning to look even more beautiful!
I see that there are some bytes before the name and some after. And I know that somewhere in those bytes I have a date. Sometimes, developers get creative with dates and make up ways to represent them. We will first assume the creator of this file used a standard way to represent dates and hope for the best. Otherwise, this might get TOO interesting.
12/07/1975 converted to Epoch timestamp is 187’142.400 (I used this site to get that value). And that converted to HEX is 0xB279100. Let’s try to find that number in our data… I don’t see it…
Oops, it’s not that easy then.
But I’m not loosing hope. We still have some known ways to represent dates. For example milliseconds instead of seconds, so converting 187’142.400 * 1.000 to HEX we get 0x2B928E6800. Let’s look again… I don’t see that number either… But I do see something that looks similar.

These are the same numbers but reversed, funny. Remember the stories about the endians, the big and the small? We just found out something else about our file, it stores the numbers in big endian format. So 0x2B928E6800 is saved as 00688E922B. This is 5 bytes long, an odd number of bytes, and — remember — I like beautiful, round, even numbers. I don’t like odd numbers. So my sixth sense tells me this date must be stored in 8 bytes. And that is exactly the amount of bytes I have before the name in each record. So now, we only have to figure out the bytes after the name.
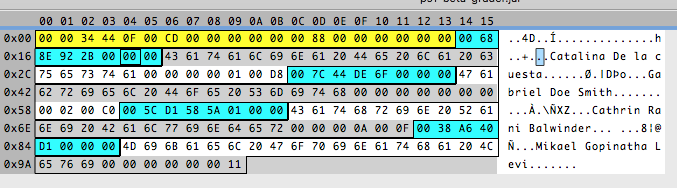
Strings usually end with a 0 and, if the field is bigger than the name length, it’s filled with 0s. That would tell us that the name field size is 25. An odd number! But when talking about strings fields, I don’t really care that it is odd. And 25 is still a really pretty number. That leaves us with just three more bytes.
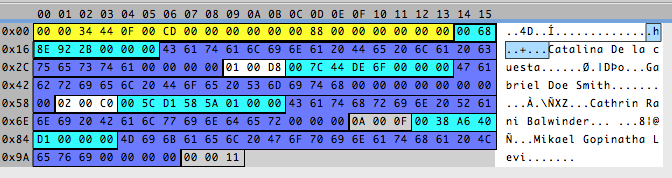
Three? Another odd number? What does it tell me? Usually bytes that are number values are stored in 2,4,8… bytes. But sometimes, a byte is used to represent something that is not a number but “yes or no” values, called flags, where each bit of the byte has a meaning. If that is the case we have two bytes for the number of pets and one byte for flags, where probably each bit represents a hobby. Looking at the numbers in the app and the bytes in the file, and knowing that numbers are stored in big endian format, I can deduce that the first two bytes after the name are the number of pets and the last byte is a flag.
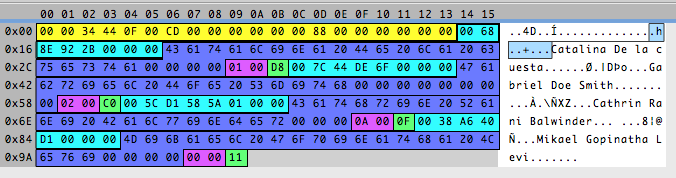
It looks so beautiful! ❤️
The Extras
What about the flags, how do we interpret them? This part is tricky, and usually you need a fair amount of data to be able to tell which bit represents which hobby, or be able to play with the application changing one hobby at a time and seeing what bit is changed. For example, the flag for Catalina’s record is 0xD8, in binary, it corresponds to 11011000, and the hobbies are Sewing, Reading, Singing and Dancing, probably corresponding to bits 3, 4, 6 and 7. If I go to the application, change the profile so that “Reading” is no longer a hobby and the byte changes to 11001000, I can tell that bit 4 represents “Reading.”
The Beautiful Pattern
Told you! It all makes sense! It’s not random, unreadable or a mess. It’s a beautiful pattern just standing in front of us.
There are no mysteries for us now. We know what each byte of the file means, and we can extract any data we need directly from the file. We can even write a parser that helps us do it automatically, because we now know the schema. This is probably something that you won’t need to do often, but it’s a really nice brain exercise. And, who knows, maybe you will need to use this too, as I did, to help solve a client’s problem.
Want to be alerted when we publish future blogs? Sign up for our newsletter!