How to Improve a Real-Time Data Processing Pipeline Using AWS - From Legacy Data Management Solutions to the Cloud, a Case Study

What does Real-Time data processing mean?
In real-time data processing (also called real-time data streaming), data streams, which are continuous never ending streams of data, are processed, stored and analyzed as the data is received.
Real-time data processing challenges are very complex. Scalability, consistency, durability, fault tolerance, and data guarantees require a well-designed architecture in order to ensure the good quality of the information your company receives.
Legacy data management and transformation solutions are largely unable to keep up with the demands of real-time data processing requirements.
Batch Processing vs Real-Time Streams
Legacy batch data processing methods require data to be collected before it can be processed, stored or analyzed.
In real-time streaming, the data flows in continuously, allowing data from many different sources to be processed in real time without waiting for it to arrive in batch form.
Case Study - Corgibytes Client
One of our clients produces unique planners and appointment books. They are known as “America’s Premier Journal Innovator” and is highly regarded throughout the promotional products industry as the category leader of custom journals and notebooks.
What is the driven force behind the change in the architecture?
The client’s admin website used to receive master data information about orders, invoices, shipments, and customers from an ERP system we will call System One. The client decided to replace System One with a new system we’ll call System Two. System Two has a different data processing model.
How did System One send information to the website? System One used to collect information about different transactions, create a batch file, and send that information to an FTP server. Their website used to receive these batch files. A Cron job on the web server used to process these files and save the data to the website’s database.
When the client switched to System Two, we decided that, in order to minimize the changes to the website, the best option would be to create a System Two shim to format System Two data so it looks the same as it did from System One. Instead of working on a legacy solution, we decided to use AWS Data Streams to ingest the data.
AWS Services Utilized - Quick Overview
-
Amazon Kinesis Data Streams (KDS) : It is a massively scalable and durable real-time data streaming service. KDS can continuously capture gigabytes of data per second from hundreds of thousands of sources. The data collected is available in milliseconds to enable real-time analytics use cases. Benefits: Real-time performance, durable, secure, easy to use, elastic, low cost.
-
Amazon Kinesis Data Firehose (KDF): It is the easiest way to reliably load streaming data into data lakes, data stores, and analytics services. It can capture, transform, and deliver streaming data to Amazon S3, Amazon Redshift, Amazon Elasticsearch Service, generic HTTP endpoints, and service providers like Datadog, New Relic, MongoDB, and Splunk.
-
AWS Lambda: AWS Lambda is a serverless computer service that lets you run code without provisioning or managing servers
-
API Gateway: Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor, and secure APIs at any scale. APIs act as the “front door” for applications to access data, business logic, or functionality from your backend services. Using API Gateway, you can create RESTful APIs and WebSocket APIs that enable real-time two-way communication applications.
-
Amazon Simple Storage Service (S3): It is an object storage service that offers scalability, data availability, security, and performance.
Implemented Solution: API Gateway + AWS Kinesis Data Streams + Kinesis Firehose + S3
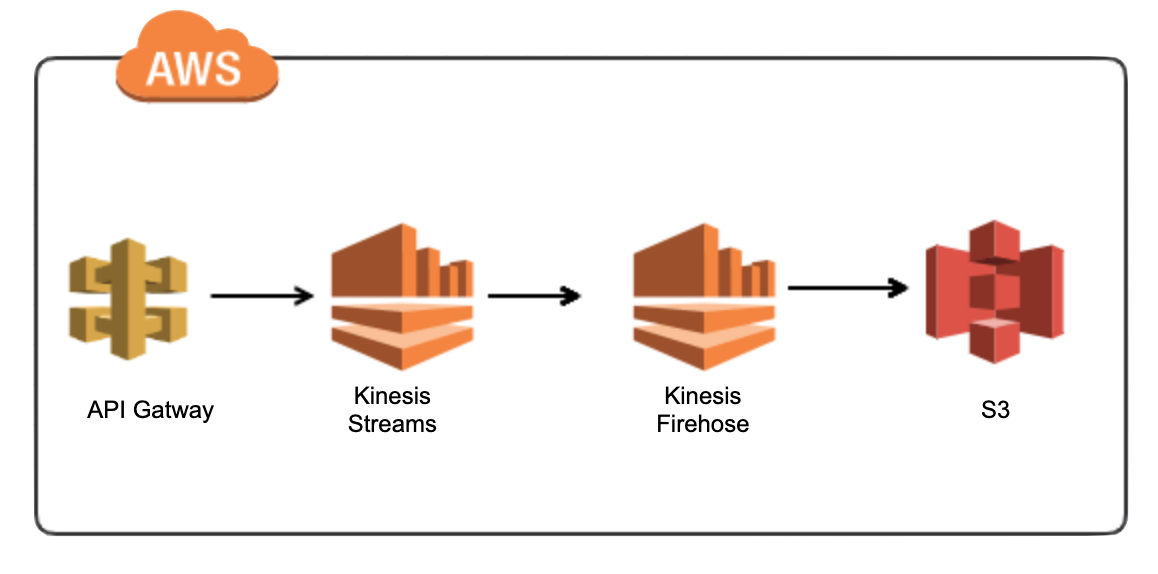
The import flow starts in System Two, which has an event-driven model that allows us to make HTTP calls on pre-configured events. When an entity changes in System Two, a System Two Event Connect is triggered. This event makes an HTTPS call to an import API exposed as an AWS API Gateway.
The API Gateway receives the HTTPS call, identifies the type of stream through the URL, and sends the payload to the corresponding Kinesis data stream. There are 9 types of Kinesis Data Streams defined.
- Customers: Updates Customers Information
- Orders: Updates Orders Information
- Order Lines: Updates Order Lines information
- Invoices: Updates Invoices information
- Invoice Lines: Updates Invoice Lines information
- Shipments: Updates Shipment information
- Shipping Addresses: Updates Shipping Address information.
- Virtual Requests: Updates Virtual Requests information needed for Creative Queue virtuals
- Estimates: This stream updates the quote number and version in Orders.
- The Kinesis Data Stream receives the payload and sends it to the corresponding Kinesis Data Firehose.
The Kinesis Data Firehose sends the payload to a Lambda transformation function, takes the output and sends it to an s3 bucket.
All the transformed payloads are sent to the same s3 bucket. The s3 bucket is on sync with the the client’s website. The sync is setup via s3fs.
The import process (which is running as a cron job) takes these files, process them and save them into the database.
Conclusion:
-
We can see improvements in the time the data is processed because it is received in real time now, instead of the System One batch file.
-
The data pipeline can still be improved by removing the cron job and ingesting the data directly into the database. We decided to go slow but steady. Changes does not need to be made all together.
-
We moved to a more robust and scalable solution by using AWS components that were specially designed to process data in real-time.
-
The entire architecture can be versioned since it was created by implementing infrastructure as code using Terraform (not covered in this blog post).
Want to be alerted when we publish future blogs? Sign up for our newsletter!